|
|
| (11 intermediate revisions by the same user not shown) |
| Line 1: |
Line 1: |
| | = Software - what is run by each test = |
|
| |
|
| Libreswan comes with an extensive test suite, written mostly in python, that uses KVM virtual machines and virtual networks. It has replaced the old UML test suite.
| | == Boot the VMs == |
| Apart from KVM, the test suite uses libvirtd and qemu. It is strongly recommended to run the test suite natively on the OS (not in a VM itself) on a machine that has a CPU wth virtualization instructions.
| |
| The PLAN9 filesystem (9p) is used to mount host directories in the guests - NFS is avoided to prevent network lockups when an IPsec test case would cripple the guest's networking.
| |
|
| |
|
| {{ ambox | nocat=true | type=important | text = libvirt 0.9.11 and qemu 1.0 or better are required. RHEL does not support a writable 9p filesystem, so the recommended host/guest OS is Fedora 22 }}
| | Before a test can be run all the VMs are (re)booted. Consequently one obvious way to speed up testing is to reduce the amount of time it takes to boot: |
|
| |
|
| [[File:testnet.png]]
| | * make the boot faster - it should be around 1s |
|
| |
|
| == Test Frameworks ==
| | * boot several machines in parallel - however booting is CPU intensive (see below for analysis) |
|
| |
|
| This page describes the make kvm framework.
| | To determine where a VM is spending its time during boot, use <tt>systemd-analyze blame</tt> (do several runs, the very first boot does extra configuration so is always be slower): |
| | |
| Instead of using virtual machines, it is possible to use Docker instances.
| |
| | |
| More information is found in [[Test Suite - Docker]] in this Wiki
| |
| | |
| == Preparing the host machine ==
| |
| | |
| In the following it is assumed that your account is called "build".
| |
| | |
| === Add Yourself to sudo ===
| |
| | |
| The test scripts rely on being able to use sudo without a password to gain root access. This is done by creating a no-pasword rule to /etc/sudoers.d/.
| |
| | |
| XXX: Surely qemu can be driven without root?
| |
| | |
| To set this up, add your account to the wheel group and permit wheel to have no-password access. Issue the following commands as root:
| |
| | |
| <pre> | |
| echo '%wheel ALL=(ALL) NOPASSWD: ALL' > /etc/sudoers.d/swantest
| |
| chmod 0440 /etc/sudoers.d/swantest
| |
| chown root.root /etc/sudoers.d/swantest
| |
| usermod -a -G wheel build
| |
| </pre> | |
| | |
| === Disable SELinux ===
| |
| | |
| SELinux blocks some actions that we need. We have not created any SELinux rules to avoid this.
| |
| | |
| Either set it to permissive:
| |
| | |
| <pre>
| |
| sudo sed --in-place=.ORIG -e 's/^SELINUX=.*/SELINUX=permissive/' /etc/selinux/config
| |
| sudo setenforce Permissive
| |
| </pre>
| |
| | |
| Or disabled:
| |
| | |
| <pre>
| |
| sudo sed --in-place=.ORIG -e 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
| |
| sudo reboot
| |
| </pre>
| |
| | |
| === Install Required Dependencies ===
| |
| | |
| Now we are ready to install the various components of libvirtd, qemu and kvm and then start the libvirtd service.
| |
| | |
| Even virt-manager isn't strictly required.
| |
| | |
| On Fedora 28:
| |
| | |
| <pre>
| |
| # is virt-manager really needed
| |
| sudo dnf install -y qemu virt-manager virt-install libvirt-daemon-kvm libvirt-daemon-qemu
| |
| sudo dnf install -y python3-pexpect
| |
| </pre>
| |
| | |
| Once all is installed start libvirtd:
| |
| | |
| <pre>
| |
| sudo systemctl enable libvirtd
| |
| sudo systemctl start libvirtd
| |
| </pre>
| |
| | |
| On Debian?
| |
| | |
| === Install Utilities (Optional) ===
| |
| | |
| Various tools are used or convenient to have when running tests:
| |
| | |
| Optional packages to install on Fedora
| |
| | |
| <pre>
| |
| sudo dnf -y install git patch tcpdump expect python-setproctitle python-ujson pyOpenSSL python3-pyOpenSSL
| |
| sudo dnf install -y python2-pexpect python3-setproctitle diffstat
| |
| </pre>
| |
| | |
| Optional packages to install on Ubuntu
| |
| | |
| <pre>
| |
| apt-get install python-pexpect git tcpdump expect python-setproctitle python-ujson \
| |
| python3-pexpect python3-setproctitle
| |
| </pre>
| |
| | |
| {{ ambox | nocat=true | type=important | text = do not install strongswan-libipsec because you won't be able to run non-NAT strongswan tests! }}
| |
| | |
| === Setting Users and Groups ===
| |
| | |
| You need to add yourself to the qemu group. For instance:
| |
|
| |
|
| <pre> | | <pre> |
| sudo usermod -a -G qemu $(id -u -n)
| | $ date ; ./testing/utils/kvmsh.py --boot cold l.east 'systemd-analyze time ; systemd-analyze critical-chain ; systemd-analyze blame' |
| </pre>
| | Mon 10 Aug 2020 09:10:06 PM EDT |
| | | virsh 0.00: waiting 20 seconds for domain to shutdown |
| You will need to re-login for this to take effect.
| | virsh 0.05: domain shutdown after 0.5 seconds |
| | virsh 0.06: starting domain |
| | virsh 11.07: got login prompt; sending 'root' and waiting 5 seconds for password (or shell) prompt |
| | virsh 11.08: got password prompt after 0.1 seconds; sending 'swan' and waiting 5 seconds for shell prompt |
| | virsh 12.00: we're in after 0.3 seconds! |
|
| |
|
| The path to your build needs to be accessible (executable) by root: | | [root@east ~]# systemd-analyze time ; systemd-analyze critical-chain ; systemd-analyze blame |
| | Startup finished in 1.270s (kernel) + 1.837s (initrd) + 4.448s (userspace) = 7.557s |
| | multi-user.target reached after 4.411s in userspace |
| | The time when unit became active or started is printed after the "@" character. |
| | The time the unit took to start is printed after the "+" character. |
|
| |
|
| <pre>
| | multi-user.target @4.411s |
| chmod a+x ~
| | └─sshd.service @4.356s +52ms |
| | └─network.target @4.350s |
| | └─systemd-networkd.service @1.236s +196ms |
| | └─systemd-udevd.service @1.003s +229ms |
| | └─systemd-tmpfiles-setup-dev.service @869ms +102ms |
| | └─kmod-static-nodes.service @644ms +115ms |
| | └─systemd-journald.socket |
| | └─system.slice |
| | └─-.slice |
| | 2.909s systemd-networkd-wait-online.service |
| | 445ms systemd-udev-trigger.service |
| | 443ms systemd-vconsole-setup.service |
| | 229ms systemd-udevd.service |
| | 209ms systemd-journald.service |
| | 196ms systemd-networkd.service |
| | 180ms systemd-tmpfiles-setup.service |
| | 178ms systemd-logind.service |
| | 145ms auditd.service |
| | 138ms source.mount |
| | 124ms testing.mount |
| | 115ms kmod-static-nodes.service |
| | 111ms systemd-journal-flush.service |
| | 110ms tmp.mount |
| | 102ms systemd-tmpfiles-setup-dev.service |
| | 99ms systemd-modules-load.service |
| | 84ms systemd-remount-fs.service |
| | 71ms systemd-random-seed.service |
| | 58ms systemd-sysctl.service |
| | 57ms dbus-broker.service |
| | 52ms sshd.service |
| | 50ms systemd-userdbd.service |
| | 33ms systemd-user-sessions.service |
| | 24ms systemd-fsck-root.service |
| | 23ms dracut-shutdown.service |
| | 21ms systemd-update-utmp.service |
| | 13ms systemd-update-utmp-runlevel.service |
| | 6ms sys-kernel-config.mount |
| | [root@east ~]# |
| </pre> | | </pre> |
|
| |
|
| === Fix /var/lib/libvirt/qemu === | | == Run the Test Scripts == |
|
| |
|
| {{ ambox | nocat=true | type=important | text = Because our VMs don't run as qemu, /var/lib/libvirt/qemu needs to be changed using chmod g+w to make it writable for the qemu group. This needs to be repeated if the libvirtd package is updated on the system }}
| | To establish a baseline, <tt>enumcheck-01</tt>, which pretty much nothing, takes ~2s to run the test scripts once things are booted: |
|
| |
|
| <pre> | | <pre> |
| sudo chmod g+w /var/lib/libvirt/qemu
| | w.runner enumcheck-01 32.08/32.05: start running scripts west:west.sh west:final.sh at 2018-10-24 22:00:44.706355 |
| | ... |
| | w.runner enumcheck-01 34.03/34.00: stop running scripts west:west.sh west:final.sh after 1.5 seconds |
| </pre> | | </pre> |
|
| |
|
| === Create /etc/modules-load.d/virtio.conf ===
| | everything else is slower. |
|
| |
|
| Several virtio modules need to be loaded into the host's kernel. This could be done by modprobe ahead of running any virtual machines but it is easier to install them whenever the host boots. This is arranged by listing the modules in a file within /etc/modules-load.d. The host must be rebooted for this to take effect.
| | To get a list of script times: |
|
| |
|
| <pre> | | <pre> |
| sudo dd <<EOF of=/etc/modules-load.d/virtio.conf
| | $ awk '/: stop running scripts/ { print $3, $(NF-1) }' testing/pluto/*/OUTPUT/debug.log | sort -k2nr | head -5 |
| virtio_blk
| | newoe-05-hold-pass 295.6 |
| virtio-rng
| | newoe-04-pass-pass 226.7 |
| virtio_console
| | ikev2-01-fallback-ikev1 212.5 |
| virtio_net
| | newoe-10-expire-inactive-ike 205.6 |
| virtio_scsi
| | ikev2-32-nat-rw-rekey 205.4 |
| virtio
| |
| virtio_balloon
| |
| virtio_input
| |
| virtio_pci
| |
| virtio_ring
| |
| 9pnet_virtio
| |
| EOF
| |
| </pre> | | </pre> |
|
| |
|
| As of Fedora 28, several of these modules are now built into the kernel and will not show up in /proc/modules (virtio, virtio_rng, virtio_pci, virtio_ring).
| | which can then be turned into a histogram: |
| | |
| === Ensure that the host has enough entropy ===
| |
|
| |
|
| [[Entropy matters]] | | [[File:Test-script-time-histogram.jpg]] |
|
| |
|
| With KVM, a guest systems uses entropy from the host through the kernel module "virtio_rng" in the guest's kernel (set above). This has advantages:
| | === sleep === |
| | === ping === |
| | === timeout === |
|
| |
|
| * entropy only needs to be gathered on one machine (the host) rather than all machines (the host and the guests)
| | == Perform Post-mortem == |
| * the host is in the Real World and thus has more sources of real entropy
| |
| * any hacking to make entropy available need only be done on one machine
| |
|
| |
|
| To ensure the host has enough randomness, run either jitterentropy-rngd or havegd.
| | This seems to be in the noise vis: |
|
| |
|
| Fedora commands for using jitterentropy-rngd (broken on F26, service file specifies /usr/local for path):
| |
| <pre> | | <pre> |
| sudo dnf install jitterentropy-rngd
| | m1.runner ipsec-hostkey-ckaid-01 12:44:50.01: start post-mortem ipsec-hostkey-ckaid-01 (test 725 of 739) at 2018-10-25 09:40:49.748041 |
| sudo systemctl enable jitterentropy-rngd
| | m1.runner ipsec-hostkey-ckaid-01 12:44:50.03: ****** ipsec-hostkey-ckaid-01 (test 725 of 739) passed ****** |
| sudo systemctl start jitterentropy-rngd
| | m1.runner ipsec-hostkey-ckaid-01 12:44:50.03: stop post-mortem ipsec-hostkey-ckaid-01 (test 725 of 739) after 0.2 seconds |
| </pre> | | </pre> |
|
| |
|
| Fedora commands for using havegd:
| | = KVM Hardware = |
|
| |
|
| <pre>
| | What the test runs on |
| sudo dnf install haveged
| |
| sudo systemctl enable haveged
| |
| sudo systemctl start haveged
| |
| </pre>
| |
|
| |
|
| === Fetch Libreswan === | | == Disk I/O == |
|
| |
|
| The libreswan source tree includes all the components that are used on the host and inside the test VMs. To get the latest source code using git:
| | Something goes here? |
|
| |
|
| <pre>
| | == Memory == |
| git clone https://github.com/libreswan/libreswan
| |
| cd libreswan
| |
| </pre>
| |
|
| |
|
| === Experimental: label source tree for SELinux ===
| | How much is needed? |
| This only matters if you are using Fedora and have not disabled SELinux.
| |
|
| |
|
| The source tree on the host is shared with the virtual machines. SELinux considers this a bug unless the tree is labelled with type svirt_image_t.
| | == CPU == |
| <pre>
| |
| sudo dnf install policycoreutils-python-utils
| |
| sudo semanage fcontext -a -t svirt_image_t "$(pwd)"'(/.*)?'
| |
| sudo restorecon -vR /home/build/libreswan
| |
| </pre>
| |
|
| |
|
| There may be other things that SELinux objects to.
| | Anything Here? Allowing use of HOST's h/w accelerators? |
|
| |
|
| === Create the Pool directory - KVM_POOLDIR === | | = Docker Hardware = |
|
| |
|
| The pool directory is used used to store KVM disk images and other configuration files. By default $(top_srcdir)/../pool is used (that is, adjacent to your source tree).
| | ? |
|
| |
|
| To change the location of the pool directory, set the KVM_POOLDIR make variable in Makefile.inc.local. For instance:
| | = Tuning kvm performance = |
| | |
| <pre>
| |
| $ grep KVM_POOLDIR Makefile.inc.local
| |
| KVM_POOLDIR=/home/libreswan/pool
| |
| </pre>
| |
| | |
| == Serve test results as HTML pages on the test server (optional) ==
| |
| | |
| If you want to be able to see the results of testruns in HTML, you can enable a webserver:
| |
| | |
| <pre>
| |
| dnf install httpd
| |
| systemctl enable httpd
| |
| systemctl start httpd
| |
| mkdir /var/www/html/results/
| |
| chown build /var/www/html/results/
| |
| chmod 755 /var/www/html/results/
| |
| cd ~
| |
| ln -s /var/www/html/results
| |
| </pre>
| |
| | |
| If you want it to be the main page of the website, you can create the file /var/www/html/index.html containing:
| |
| | |
| <pre>
| |
| <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
| |
| <html>
| |
| <head>
| |
| <meta http-equiv="REFRESH" content="0;url=/results/"></HEAD>
| |
| <BODY>
| |
| </BODY>
| |
| </HTML>
| |
| </pre>
| |
| | |
| and then add:
| |
| | |
| <pre>
| |
| WEB_SUMMARYDIR=/var/www/html/results
| |
| </pre>
| |
| | |
| To Makefile.inc.local
| |
| | |
| == Set up KVM and run the Testsuite (for the impatient) ==
| |
| | |
| If you're impatient, and want to just run the testsuite using kvm then:
| |
| | |
| * install (or update) libreswan (if needed this will create the test domains):
| |
| : <tt>make kvm-install</tt>
| |
| * run the testsuite:
| |
| : <tt>make kvm-test</tt>
| |
| * list the kvm make targets:
| |
| : <tt>make kvm-help</tt>
| |
| | |
| After that, the following make targets are useful:
| |
| | |
| * clean the kvm build tree
| |
| : <tt>make kvm-clean</tt>
| |
| * clean the kvm build tree and all kvm domains
| |
| : <tt>make kvm-purge</tt>
| |
| | |
| == Running the testsuite ==
| |
| | |
| === Generating Certificates ===
| |
| | |
| The full testsuite requires a number of certificates. The virtual domains are configured for this purpose. Just use:
| |
| | |
| <pre>
| |
| make kvm-keys
| |
| </pre>
| |
| | |
| ( ''Before pyOpenSSL version 0.15 you couldn't run dist_certs.py without a patch to support creating SHA1 CRLs.
| |
| A patch for this can be found at'' https://github.com/pyca/pyopenssl/pull/161 )
| |
| | |
| === Run the testsuite ===
| |
| | |
| To run all test cases (which include compiling and installing it on all vms, and non-VM based test cases), run:
| |
| | |
| <pre>
| |
| make kvm-install kvm-test
| |
| </pre>
| |
| | |
| === Stopping pluto tests (gracefully) ===
| |
| | |
| If you used "make kvm-test", type control-C; possibly repeatedly.
| |
| | |
| == Shell and Console Access (Logging In) ==
| |
| | |
| There are several different ways to gain shell access to the domains.
| |
| | |
| Each method, depending on the situation, has both advantages and disadvantages. For instance:
| |
| | |
| * while make kvmsh-host provide quick access to the console, it doesn't support file copy
| |
| * while SSH takes more to set up, it supports things like proper terminal configuration and file copy
| |
| | |
| === Serial Console access using "make kvmsh-HOST" (kvmsh.py) ===
| |
| | |
| "kvmsh", is a wrapper around "virsh". It automatically handles things like booting the machine, logging in, and correctly configuring the terminal:
| |
| | |
| <pre>
| |
| $ ./testing/utils/kvmsh.py east
| |
| [...]
| |
| Escape character is ^]
| |
| [root@east ~]# printenv TERM
| |
| xterm
| |
| [root@east ~]# stty -a
| |
| ...; rows 52; columns 185; ...
| |
| [root@east ~]#
| |
| </pre>
| |
| | |
| "kvmsh.py" can also be used to script remote commands (for instance, it is used to run "make" on the build domain):
| |
| | |
| <pre>
| |
| $ ./testing/utils/kvmsh.py east ls
| |
| [root@east ~]# ls
| |
| anaconda-ks.cfg
| |
| </pre>
| |
| | |
| Finally, "make kvmsh-HOST" provides a short cut for the above; and if your using multiple build trees (see further down), it will connect to the DOMAIN that corresponds to HOST. For instance, notice how the domain "a.east" is passed to kvmsh.py in the below:
| |
| | |
| <pre>
| |
| $ make kvmsh-east
| |
| /home/libreswan/pools/testing/utils/kvmsh.py --output ++compile-log.txt --chdir . a.east
| |
| Escape character is ^]
| |
| [root@east source]#
| |
| </pre>
| |
| | |
| Limitations:
| |
| | |
| * no file transfer but files can be accessed via /testing
| |
| | |
|
| |
| === Graphical Console access using virt-manager ===
| |
|
| |
| "virt-manager", a gnome tool can be used to access individual domains.
| |
| | |
| While easy to use, it doesn't support cut/paste or mechanisms for copying files.
| |
| | |
| | |
| === Shell access using SSH ===
| |
| | |
| While requiring slightly more effort to set up, it provides full shell access to the domains.
| |
| | |
| Since you will be using ssh a lot to login to these machines, it is recommended to either put their names in /etc/hosts:
| |
| | |
| <pre>
| |
| # /etc/hosts entries for libreswan test suite
| |
| 192.1.2.45 west
| |
| 192.1.2.23 east
| |
| 192.0.3.254 north
| |
| 192.1.3.209 road
| |
| 192.1.2.254 nic
| |
| </pre>
| |
| | |
| or add entries to .ssh/config such as:
| |
| | |
| <pre>
| |
| Host west
| |
| Hostname 192.1.2.45
| |
| </pre>
| |
| | |
| If you wish to be able to ssh into all the VMs created without using a password, add your ssh public key to '''testing/baseconfigs/all/etc/ssh/authorized_keys'''. This file is installed as /root/.ssh/authorized_keys on all VMs
| |
| | |
| Using ssh becomes easier if you are running ssh-agent (you probably are) and your public key is known to the virtual machine. This command, run on the host, installs your public key on the root account of the guest machines west. This assumes that west is up (it might not be, but you can put this off until you actually need ssh, at which time the machine would need to be up anyway). Remember that the root password on each guest machine is "swan".
| |
| <pre>
| |
| ssh-copy-id root@west
| |
| </pre>
| |
| You can use ssh-copy for any VM. Unfortunately, the key is forgotten when the VM is restarted.
| |
| | |
| == Run an individual test (or tests) ==
| |
| | |
| All the test cases involving VMs are located in the libreswan directory under testing/pluto/ . The most basic test case is called basic-pluto-01. Each test case consists of a few files:
| |
| | |
| * description.txt to explain what this test case actually tests
| |
| * ipsec.conf files - for host west is called west.conf. This can also include configuration files for strongswan or racoon2 for interop testig
| |
| * ipsec.secret files - if non-default configurations are used. also uses the host syntax, eg west.secrets, east.secrets.
| |
| * An init.sh file for each VM that needs to start (eg westinit.sh, eastinit.sh, etc)
| |
| * One run.sh file for the host that is the initiator (eg westrun.sh)
| |
| * Known good (sanitized) output for each VM (eg west.console.txt, east.console.txt)
| |
| * testparams.sh if there are any non-default test parameters
| |
| | |
| You can run this test case by issuing the following command on the host:
| |
| | |
| Either:
| |
| | |
| <pre>
| |
| make kvm-test KVM_TESTS+=testing/pluto/basic-pluto-01/
| |
| </pre>
| |
| | |
| or:
| |
| | |
| <pre>
| |
| ./testing/utils/kvmtest.py testing/pluto/basic-pluto-01
| |
| </pre>
| |
| | |
| multiple tests can be selected with:
| |
| | |
| <pre>
| |
| make kvm-test KVM_TESTS+=testing/pluto/basic-pluto-*
| |
| </pre>
| |
| | |
| or:
| |
| | |
| <pre>
| |
| ./testing/utils/kvmresults.py testing/pluto/basic-pluto-*
| |
| </pre>
| |
| | |
| Once the test run has completed, you will see an OUTPUT/ directory in the test case directory:
| |
| | |
| <pre>
| |
| $ ls OUTPUT/
| |
| east.console.diff east.console.verbose.txt RESULT west.console.txt west.pluto.log
| |
| east.console.txt east.pluto.log swan12.pcap west.console.diff west.console.verbose.txt
| |
| </pre>
| |
| | |
| * RESULT is a text file (whose format is sure to change in the next few months) stating whether the test succeeded or failed.
| |
| * The diff files show the differences between this testrun and the last known good output.
| |
| * Each VM's serial (sanitized) console log (eg west.console.txt)
| |
| * Each VM's unsanitized verbose console output (eg west.console.verbose.txt)
| |
| * A network capture from the bridge device (eg swan12.pcap)
| |
| * Each VM's pluto log, created with plutodebug=all (eg west.pluto.log)
| |
| * Any core dumps generated if a pluto daemon crashed
| |
| | |
| == Debugging inside the VM ==
| |
| | |
| === Debugging pluto on east ===
| |
| | |
| Terminal 1 - east: log into east, start pluto, and attach gdb
| |
| | |
| <pre>
| |
| make kvmsh-east
| |
| east# cd /testing/pluto/basic-pluto-01
| |
| east# sh -x ./eastinit.sh
| |
| east# gdb /usr/local/libexec/ipsec/pluto $(pidof pluto)
| |
| (gdb) c
| |
| </pre>
| |
| | |
| Terminal 2 - west: log into west, start pluto and the test
| |
| | |
| <pre>
| |
| make kvmsh-west
| |
| west# sh -x ./westinit.sh ; sh -x westrun.sh
| |
| </pre>
| |
| If pluto wasn't running, gdb would complain: ''<code>--p requires an argument</code>''
| |
| | |
| When pluto crashes, gdb will show that and await commands. For example, the bt command will show a backtrace.
| |
| | |
| === Debugging pluto on west ===
| |
| | |
| See above, but also use virt as a terminal.
| |
| | |
| === /root/.gdbinit ===
| |
| | |
| If you want to get rid of the warning "warning: File "/testing/pluto/ikev2-dpd-01/.gdbinit" auto-loading has been declined by your `auto-load safe-path'"
| |
| | |
| <pre>
| |
| echo "set auto-load safe-path /" >> /root/.gdbinit
| |
| </pre>
| |
| | |
| == Updating the VMs ==
| |
| | |
| # delete all the copies of the base VM:
| |
| #: <tt>$ make kvm-purge</tt>
| |
| # install again
| |
| #: <tt>$ make kvm-install</tt>
| |
| | |
| == The /testing/guestbin directory ==
| |
| | |
| The guestbin directory contains scripts that are used within the VMs only.
| |
| | |
| === swan-transmogrify ===
| |
| | |
| When the VMs were installed, an XML configuration file from testing/libvirt/vm/ was used to configure each VM with the right disks, mounts and nic cards. Each VM mounts the libreswan directory as /source and the libreswan/testing/ directory as /testing . This makes the /testing/guestbin/ directory available on the VMs. At boot, the VMs run /testing/guestbin/swan-transmogrify. This python script compares the nic of eth0 with the list of known MAC addresses from the XML files. By identifying the MAC, it knows which identity (west, east, etc) it should take on. Files are copied from /testing/baseconfigs/ into the VM's /etc directory and the network service is restarted.
| |
| | |
| === swan-build, swans-install, swan-update ===
| |
| | |
| These commands are used to build, install or build+install (update) the libreswan userland and kernel code
| |
| | |
| === swan-prep ===
| |
| | |
| This command is run as the first command of each test case to setup the host. It copies the required files from /testing/baseconfigs/ and the specific test case files onto the VM test machine. It does not start libreswan. That is done in the "init.sh" script.
| |
| | |
| The swan-prep command takes two options.
| |
| The --x509 option is required to copy in all the required certificates and update the NSS database.
| |
| The --46 /--6 option is used to give the host IPv4 and/or IPv6 connectivity. Hosts per default only get IPv4 connectivity as this reduces the noise captured with tcpdump
| |
| | |
| === fipson and fipsoff ===
| |
| | |
| These are used to fake a kernel into FIPS mode, which is required for some of the tests.
| |
| | |
| | |
| == Various notes ==
| |
| | |
| * Currently, only one test can run at a time.
| |
| * You can peek at the guests using virt-manager or you can ssh into the test machines from the host.
| |
| * ssh may be slow to prompt for the password. If so, start up the vm "nic"
| |
| * On VMs use only one CPU core. Multiple CPUs may cause pexpect to mangle output.
| |
| * 2014 Mar: DHR needed to do the following to make things work each time he rebooted the host
| |
| <pre>
| |
| $ sudo setenforce Permissive
| |
| $ ls -ld /var/lib/libvirt/qemu
| |
| drwxr-x---. 6 qemu qemu 4096 Mar 14 01:23 /var/lib/libvirt/qemu
| |
| $ sudo chmod g+w /var/lib/libvirt/qemu
| |
| $ ( cd testing/libvirt/net ; for i in * ; do sudo virsh net-start $i ; done ; )
| |
| </pre>
| |
| * to make the SELinux enforcement change persist across host reboots, edit /etc/selinux/config
| |
| * to remove "169.254.0.0/16 dev eth0 scope link metric 1002" from "ipsec status output"
| |
| <pre> echo 'NOZEROCONF=1' >> /etc/sysconfig/network </pre>
| |
| | |
| === Need Strongswan 5.3.2 or later ===
| |
| The baseline Strongswan needed for our interop tests is 5.3.2. This isn't part of Fedora or RHEL/CentOS at this time (2015 September).
| |
| | |
| Ask Paul for a pointer to the required RPM files.
| |
| | |
| Strongswan has dependency libtspi.so.1
| |
| <pre>
| |
| sudo dnf install trousers
| |
| sudo rpm -ev strongswan
| |
| sudo rpm -ev strongswan-libipsec
| |
| sudo rpm -i strongswan-5.2.0-4.fc20.x86_64.rpm
| |
| </pre>
| |
| | |
| To update to a newer verson, place the rpm in the source tree on the host machine. This avoids needing to connect the guests to the internet. Then start up all the machines, wait until they are booted, and update the Strongswan package on each machine. (DHR doesn't know which machines actually need a Strongswan.)
| |
| <pre>
| |
| for vm in west east north road ; do sudo virsh start $vm; done
| |
| # wait for booting to finish
| |
| for vm in west east north road ; do ssh root@$vm 'rpm -Uv /source/strongswan-5.3.2-1.0.lsw.fc21.x86_64.rpm' ; done
| |
| </pre>
| |
| | |
| == To improve ==
| |
| * install and remove RPM using swantest + make rpm support
| |
| * add summarizing script that generate html/json to git repo
| |
| * cordump. It has been a mystery :) systemd or some daemon appears to block coredump on the Fedora 20 systems.
| |
| * when running multiple tests from TESTLIST shutdown the hosts before copying OUTPUT dir. This way we get leak detect inf. However, for single test runs do not shut down.
| |
| | |
| == IPv6 tests ==
| |
| IPv6 test cases seems to work better when IPv6 is disabled on the KVM bridge interfaces the VMs use. The bridges are swanXX and their config files are /etc/libvirt/qemu/networks/192_0_1.xml . Remove the following line from it. Reboot/restart libvirt.
| |
| | |
| <pre>
| |
| libvirt/qemu/networks/192_0_1.xml
| |
| | |
| <ip family="ipv6" address="2001:db8:0:1::253" prefix="64"/>
| |
| | |
| </pre>
| |
| | |
| and ifconfig swan01 should have no IPv6 address, no fe:80 or any v6 address. Then the v6 testcases should work.
| |
| | |
| <br> please give me feedback if this hack work for you. I shall try to add more info about this.
| |
| | |
| == Sanitizers ==
| |
| * summarize output from tcpdump
| |
| * count established IKE, ESP , AH states (there is count at the end of "ipsec status " that is not accurate. It counts instantiated connection as loaded.
| |
| | |
| * dpd ping sanitizer. DPD tests have unpredictable packet loss for ping.
| |
| | |
| == Publishing Results on the web: http://testing.libreswan.org/results/ ==
| |
| | |
| This is experimental and uses:
| |
| | |
| * CSS
| |
| * javascript
| |
| | |
| Two scripts are available:
| |
| | |
| * <tt>testing/web/setup.sh</tt>
| |
| : sets up the directory <tt>~/results</tt> adding any dependencies
| |
| * <tt>testing/web/publish.sh</tt>
| |
| : runs the testsuite and then copies the results to <tt>~/results</tt>
| |
| | |
| To view this, use file:///.
| |
| | |
| To get this working with httpd (Apache web server):
| |
| | |
| <pre>
| |
| sudo systemctl enable httpd
| |
| sudo systemctl start httpd
| |
| sudo ln -s ~/results /var/www/html/
| |
| sudo sh -c 'echo "AddType text/plain .diff" >/etc/httpd/conf.d/diff.conf'
| |
| </pre>
| |
| | |
| To view the results, use http://localhost/results.
| |
| | |
| == Speeding up "make kvm-test" by running things in parallel ==
| |
|
| |
|
| Internally kvmrunner.py has two work queues: | | Internally kvmrunner.py has two work queues: |
| Line 590: |
Line 144: |
| * repeat | | * repeat |
|
| |
|
| My adjusting KVM_WORKERS and KVM_PREFIXES it is possible:
| | By adjusting KVM_WORKERS and KVM_PREFIXES it is possible to: |
|
| |
|
| * speed up test runs | | * speed up test runs |
| * run independent testsuites in parallel | | * run independent testsuites in parallel |
|
| |
|
| === The reboot thread pool - make KVM_WORKERS=... === | | By adjusting KVM_LOCALDIR it is possible to: |
| | |
| | * use a faster disk or even tmpfs (on /tmp) |
| | |
| | |
| | == KVM_WORKERS=... -- the number of test domains (machines) booted in parallel == |
|
| |
|
| Booting the domains is the most CPU intensive part of running a test, and trying to perform too many reboots in parallel will bog down the machine to the point where tests time out and interactive performance becomes hopeless. For this reason a pre-sized pool of reboot threads is used to reboot domains: | | Booting the domains is the most CPU intensive part of running a test, and trying to perform too many reboots in parallel will bog down the machine to the point where tests time out and interactive performance becomes hopeless. For this reason a pre-sized pool of reboot threads is used to reboot domains: |
| Line 623: |
Line 182: |
| Only if your machine has lots of cores should you consider adjusting this in Makefile.inc.local. | | Only if your machine has lots of cores should you consider adjusting this in Makefile.inc.local. |
|
| |
|
| === The tests thread pool - make KVM_PREFIXES=... ===
| |
|
| |
|
| Note that this is still somewhat experimental and has limitations:
| | == KVM_PREFIXES=... -- create a pool of test domains (machines) == |
| | |
| * stopping parallel tests requires multiple control-c's
| |
| * since the duplicate domains have the same IP address, things like "ssh east" don't apply; use "make kvmsh-<prefix><domain>" or "sudo virsh console <prefix><domain" or "./testing/utils/kvmsh.py <prefix><domain>".
| |
|
| |
|
| Tests spend a lot of their time waiting for timeouts or slow tasks to complete. So that tests can be run in parallel the KVM_PREFIX provides a list of prefixes to add to the host names forming unique domain groups that can each be used to run tests: | | Tests spend a lot of their time waiting for timeouts or slow tasks to complete. So that tests can be run in parallel the KVM_PREFIX provides a list of prefixes to add to the host names forming unique domain groups that can each be used to run tests: |
| Line 683: |
Line 238: |
| Two domain groups (e.x., KVM_PREFIX=a. b.) seems to give the best results. | | Two domain groups (e.x., KVM_PREFIX=a. b.) seems to give the best results. |
|
| |
|
| === Recommendations === | | Note that this is still somewhat experimental and has limitations: |
| | |
| | * stopping parallel tests requires multiple control-c's |
| | * since the duplicate domains have the same IP address, things like "ssh east" don't apply; use "make kvmsh-<prefix><domain>" or "sudo virsh console <prefix><domain" or "./testing/utils/kvmsh.py <prefix><domain>". |
| | |
| | |
| | == KVM_LOCALDIR=/tmp/pool -- the directory containing the test domain (machine) disks == |
| | |
| | To reduce disk I/O, it is possible to store the test domain disks in ram using tmpfs and /tmp. Here's a nice graph illustrating what happens when the option is set: |
| | |
| | [[File:Diskstats iops-day.png]] |
| | |
| | |
| | == Recommendations == |
|
| |
|
| ==== Some Analysis ====
| | === Some Analysis === |
|
| |
|
| The test system: | | The test system: |
| Line 719: |
Line 287: |
| Notice how having more than #cores/2 KVM_WORKERS (here 2) has little benefit and failures edge upwards. | | Notice how having more than #cores/2 KVM_WORKERS (here 2) has little benefit and failures edge upwards. |
|
| |
|
| ==== Desktop Development Directory ====
| | === Desktop Development Directory === |
|
| |
|
| * reduce build/install time - use only one prefix | | * reduce build/install time - use only one prefix |
| Line 740: |
Line 308: |
| but that, unfortunately, slows down the the build/install time. | | but that, unfortunately, slows down the the build/install time. |
|
| |
|
| ==== Desktop Baseline Directory ====
| | === Desktop Baseline Directory === |
|
| |
|
| * do not overload the desktop - reduce CPU load by booting sequentially | | * do not overload the desktop - reduce CPU load by booting sequentially |
| Line 751: |
Line 319: |
| * KVM_PREFIX= b1. b2. | | * KVM_PREFIX= b1. b2. |
|
| |
|
| ==== Dedicated Test Server ====
| | === Dedicated Test Server === |
|
| |
|
| * minimize total testsuite time | | * minimize total testsuite time |
Software - what is run by each test
Boot the VMs
Before a test can be run all the VMs are (re)booted. Consequently one obvious way to speed up testing is to reduce the amount of time it takes to boot:
- make the boot faster - it should be around 1s
- boot several machines in parallel - however booting is CPU intensive (see below for analysis)
To determine where a VM is spending its time during boot, use systemd-analyze blame (do several runs, the very first boot does extra configuration so is always be slower):
$ date ; ./testing/utils/kvmsh.py --boot cold l.east 'systemd-analyze time ; systemd-analyze critical-chain ; systemd-analyze blame'
Mon 10 Aug 2020 09:10:06 PM EDT
virsh 0.00: waiting 20 seconds for domain to shutdown
virsh 0.05: domain shutdown after 0.5 seconds
virsh 0.06: starting domain
virsh 11.07: got login prompt; sending 'root' and waiting 5 seconds for password (or shell) prompt
virsh 11.08: got password prompt after 0.1 seconds; sending 'swan' and waiting 5 seconds for shell prompt
virsh 12.00: we're in after 0.3 seconds!
[root@east ~]# systemd-analyze time ; systemd-analyze critical-chain ; systemd-analyze blame
Startup finished in 1.270s (kernel) + 1.837s (initrd) + 4.448s (userspace) = 7.557s
multi-user.target reached after 4.411s in userspace
The time when unit became active or started is printed after the "@" character.
The time the unit took to start is printed after the "+" character.
multi-user.target @4.411s
└─sshd.service @4.356s +52ms
└─network.target @4.350s
└─systemd-networkd.service @1.236s +196ms
└─systemd-udevd.service @1.003s +229ms
└─systemd-tmpfiles-setup-dev.service @869ms +102ms
└─kmod-static-nodes.service @644ms +115ms
└─systemd-journald.socket
└─system.slice
└─-.slice
2.909s systemd-networkd-wait-online.service
445ms systemd-udev-trigger.service
443ms systemd-vconsole-setup.service
229ms systemd-udevd.service
209ms systemd-journald.service
196ms systemd-networkd.service
180ms systemd-tmpfiles-setup.service
178ms systemd-logind.service
145ms auditd.service
138ms source.mount
124ms testing.mount
115ms kmod-static-nodes.service
111ms systemd-journal-flush.service
110ms tmp.mount
102ms systemd-tmpfiles-setup-dev.service
99ms systemd-modules-load.service
84ms systemd-remount-fs.service
71ms systemd-random-seed.service
58ms systemd-sysctl.service
57ms dbus-broker.service
52ms sshd.service
50ms systemd-userdbd.service
33ms systemd-user-sessions.service
24ms systemd-fsck-root.service
23ms dracut-shutdown.service
21ms systemd-update-utmp.service
13ms systemd-update-utmp-runlevel.service
6ms sys-kernel-config.mount
[root@east ~]#
Run the Test Scripts
To establish a baseline, enumcheck-01, which pretty much nothing, takes ~2s to run the test scripts once things are booted:
w.runner enumcheck-01 32.08/32.05: start running scripts west:west.sh west:final.sh at 2018-10-24 22:00:44.706355
...
w.runner enumcheck-01 34.03/34.00: stop running scripts west:west.sh west:final.sh after 1.5 seconds
everything else is slower.
To get a list of script times:
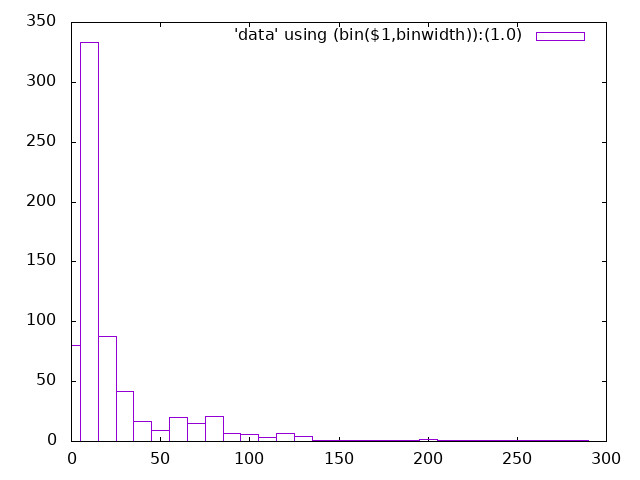
$ awk '/: stop running scripts/ { print $3, $(NF-1) }' testing/pluto/*/OUTPUT/debug.log | sort -k2nr | head -5
newoe-05-hold-pass 295.6
newoe-04-pass-pass 226.7
ikev2-01-fallback-ikev1 212.5
newoe-10-expire-inactive-ike 205.6
ikev2-32-nat-rw-rekey 205.4
which can then be turned into a histogram:
sleep
ping
timeout
Perform Post-mortem
This seems to be in the noise vis:
m1.runner ipsec-hostkey-ckaid-01 12:44:50.01: start post-mortem ipsec-hostkey-ckaid-01 (test 725 of 739) at 2018-10-25 09:40:49.748041
m1.runner ipsec-hostkey-ckaid-01 12:44:50.03: ****** ipsec-hostkey-ckaid-01 (test 725 of 739) passed ******
m1.runner ipsec-hostkey-ckaid-01 12:44:50.03: stop post-mortem ipsec-hostkey-ckaid-01 (test 725 of 739) after 0.2 seconds
KVM Hardware
What the test runs on
Disk I/O
Something goes here?
Memory
How much is needed?
CPU
Anything Here? Allowing use of HOST's h/w accelerators?
Docker Hardware
?
Tuning kvm performance
Internally kvmrunner.py has two work queues:
- a pool of reboot threads; each thread reboots one domain at a time
- a pool of test threads; each thread runs one test at a time using domains with a unique prefix
The test threads uses the reboot thread pool as follows:
- get the next test
- submit required domains to reboot pool
- wait for domains to reboot
- run test
- repeat
By adjusting KVM_WORKERS and KVM_PREFIXES it is possible to:
- speed up test runs
- run independent testsuites in parallel
By adjusting KVM_LOCALDIR it is possible to:
- use a faster disk or even tmpfs (on /tmp)
KVM_WORKERS=... -- the number of test domains (machines) booted in parallel
Booting the domains is the most CPU intensive part of running a test, and trying to perform too many reboots in parallel will bog down the machine to the point where tests time out and interactive performance becomes hopeless. For this reason a pre-sized pool of reboot threads is used to reboot domains:
- the default is 1 reboot thread limiting things to one domain reboot at a time
- KVM_WORKERS specifies the number of reboot threads, and hence, the reboot parallelism
- increasing this allows more domains to be rebooted in parallel
- however, increasing this consumes more CPU resources
To increase the size of the reboot thread pool set KVM_WORKERS. For instance:
$ grep KVM_WORKERS Makefile.inc.local
KVM_WORKERS=2
$ make kvm-install kvm-test
[...]
runner 0.019: using a pool of 2 worker threads to reboot domains
[...]
runner basic-pluto-01 0.647/0.601: 0 shutdown/reboot jobs ahead of us in the queue
runner basic-pluto-01 0.647/0.601: submitting shutdown jobs for unused domains: road nic north
runner basic-pluto-01 0.653/0.607: submitting boot-and-login jobs for test domains: east west
runner basic-pluto-01 0.654/0.608: submitted 5 jobs; currently 3 jobs pending
[...]
runner basic-pluto-01 28.585/28.539: domains started after 28 seconds
Only if your machine has lots of cores should you consider adjusting this in Makefile.inc.local.
KVM_PREFIXES=... -- create a pool of test domains (machines)
Tests spend a lot of their time waiting for timeouts or slow tasks to complete. So that tests can be run in parallel the KVM_PREFIX provides a list of prefixes to add to the host names forming unique domain groups that can each be used to run tests:
- the default is no prefix limiting things to a single global domain pool
- KVM_PREFIXES specifies the domain prefixes to use, and hence, the test parallelism
- increasing this allows more tests to be run in parallel
- however, increasing this consumes more memory and context switch resources
For instance, setting KVM_PREFIXES in Makefile.inc.local to specify a unique set of domains for this directory:
$ grep KVM_PREFIX Makefile.inc.local
KVM_PREFIX=a.
$ make kvm-install
[...]
$ make kvm-test
[...]
runner 0.018: using the serial test processor and domain prefix 'a.'
[...]
a.runner basic-pluto-01 0.574: submitting boot-and-login jobs for test domains: a.west a.east
And setting KVM_PREFIXES in Makefile.inc.local to specify two prefixes and, consequently, run two tests in parallel:
$ grep KVM_PREFIX Makefile.inc.local
KVM_PREFIX=a. b.
$ make kvm-install
[...]
$ make kvm-test
[...]
runner 0.019: using the parallel test processor and domain prefixes ['a.', 'b.']
[...]
b.runner basic-pluto-02 0.632/0.596: submitting boot-and-login jobs for test domains: b.west b.east
[...]
a.runner basic-pluto-01 0.769/0.731: submitting boot-and-login jobs for test domains: a.west a.east
creates and uses two dedicated domain/network groups (a.east ..., and b.east ...).
Finally, to get rid of all the domains use:
$ make kvm-uninstall
or even:
$ make KVM_PREFIX=b. kvm-uninstall
Two domain groups (e.x., KVM_PREFIX=a. b.) seems to give the best results.
Note that this is still somewhat experimental and has limitations:
- stopping parallel tests requires multiple control-c's
- since the duplicate domains have the same IP address, things like "ssh east" don't apply; use "make kvmsh-<prefix><domain>" or "sudo virsh console <prefix><domain" or "./testing/utils/kvmsh.py <prefix><domain>".
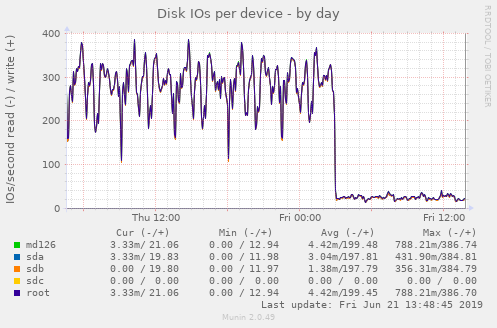
KVM_LOCALDIR=/tmp/pool -- the directory containing the test domain (machine) disks
To reduce disk I/O, it is possible to store the test domain disks in ram using tmpfs and /tmp. Here's a nice graph illustrating what happens when the option is set:
Recommendations
Some Analysis
The test system:
- 4-core 64-bit intel
- plenty of ram
- the file mk/perf.sh
Increasing the number of parallel tests, for a given number of reboot threads:
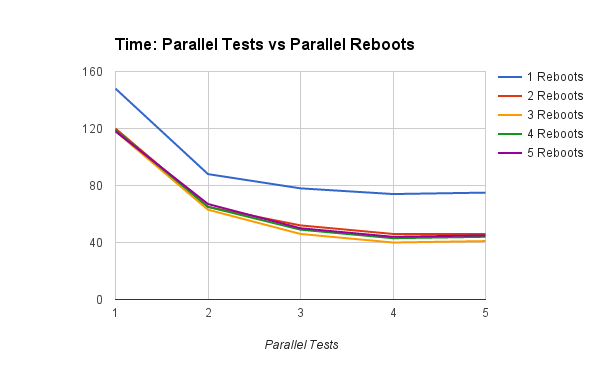
- having #cores/2 reboot threads has the greatest impact
- having more than #cores reboot threads seems to slow things down
Increasing the number of reboots, for a given number of test threads:
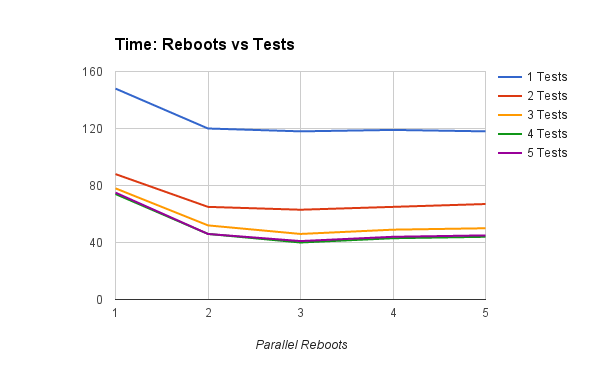
- adding a second test thread has a far greater impact than adding a second reboot thread - contrast top lines
- adding a third and even fourth test thread - i.e., up to #cores - still improves things
Finally here's some ASCII art showing what happens to the failure rate when the KVM_PREFIX is set so big that the reboot thread pool is kept 100% busy:
Fails Reboots Time
************ 127 1 6:35 ****************************************
************** 135 2 3:33 *********************
*************** 151 3 3:12 *******************
*************** 154 4 3:01 ******************
Notice how having more than #cores/2 KVM_WORKERS (here 2) has little benefit and failures edge upwards.
Desktop Development Directory
- reduce build/install time - use only one prefix
- reduce single-test time - boot domains in parallel
- use the non-prefix domains east et.al. so it is easy to access the test domains using tools like ssh
Lets assume 4 cores:
KVM_WORKERS=2
KVM_PREFIX=''
You could also add a second prefix vis:
KVM_PREFIX= '' a.
but that, unfortunately, slows down the the build/install time.
Desktop Baseline Directory
- do not overload the desktop - reduce CPU load by booting sequentially
- reduce total testsuite time - run tests in parallel
- keep separate to development directory above
Lets assume 4 cores
- KVM_WORKERS=1
- KVM_PREFIX= b1. b2.
Dedicated Test Server
- minimize total testsuite time
- maximize CPU use
- assume only testsuite running
Assuming 4 cores:
* KVM_WORKERS=2
* KVM_PREFIX= '' t1. t2. t3.



